Web scraping
![]()
Open In Colab
Use case
Web research is one of the killer LLM applications:
- Users have highlighted it as one of his top desired AI tools.
- OSS repos like gpt-researcher are growing in popularity.
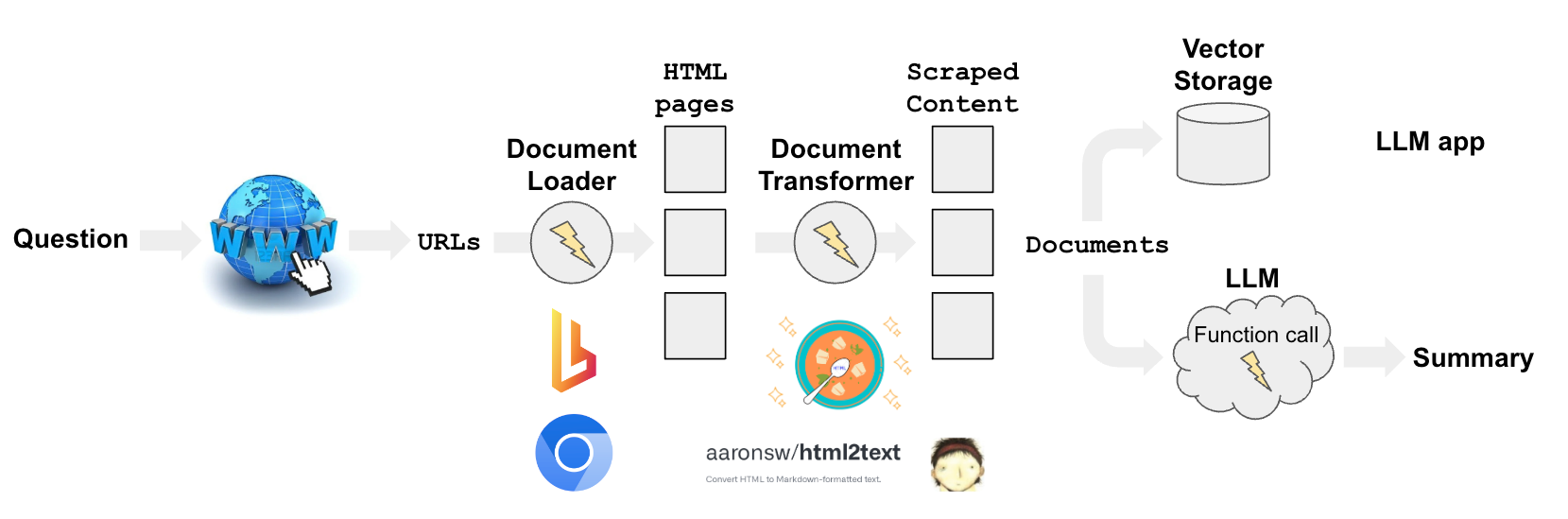
Overview
Gathering content from the web has a few components:
Search: Query to url (e.g., usingGoogleSearchAPIWrapper).Loading: Url to HTML (e.g., usingAsyncHtmlLoader,AsyncChromiumLoader, etc).Transforming: HTML to formatted text (e.g., usingHTML2TextorBeautiful Soup).
Quickstart
pip install -q langchain-openai langchain playwright beautifulsoup4
playwright install
# Set env var OPENAI_API_KEY or load from a .env file:
# import dotenv
# dotenv.load_dotenv()
Scraping HTML content using a headless instance of Chromium.
- The async nature of the scraping process is handled using Python’s asyncio library.
- The actual interaction with the web pages is handled by Playwright.
from langchain_community.document_loaders import AsyncChromiumLoader
from langchain_community.document_transformers import BeautifulSoupTransformer
# Load HTML
loader = AsyncChromiumLoader(["https://www.wsj.com"])
html = loader.load()
API Reference:
Scrape text content tags such as <p>, <li>, <div>, and <a> tags from
the HTML content:
<p>: The paragraph tag. It defines a paragraph in HTML and is used to group together related sentences and/or phrases.<li>: The list item tag. It is used within ordered (<ol>) and unordered (<ul>) lists to define individual items within the list.<div>: The division tag. It is a block-level element used to group other inline or block-level elements.<a>: The anchor tag. It is used to define hyperlinks.<span>: an inline container used to mark up a part of a text, or a part of a document.
For many news websites (e.g., WSJ, CNN), headlines and summaries are all
in <span> tags.
# Transform
bs_transformer = BeautifulSoupTransformer()
docs_transformed = bs_transformer.transform_documents(html, tags_to_extract=["span"])
# Result
docs_transformed[0].page_content[0:500]
'English EditionEnglish中文 (Chinese)日本語 (Japanese) More Other Products from WSJBuy Side from WSJWSJ ShopWSJ Wine Other Products from WSJ Search Quotes and Companies Search Quotes and Companies 0.15% 0.03% 0.12% -0.42% 4.102% -0.69% -0.25% -0.15% -1.82% 0.24% 0.19% -1.10% About Evan His Family Reflects His Reporting How You Can Help Write a Message Life in Detention Latest News Get Email Updates Four Americans Released From Iranian Prison The Americans will remain under house arrest until they are '
These Documents now are staged for downstream usage in various LLM
apps, as discussed below.
Loader
AsyncHtmlLoader
The AsyncHtmlLoader
uses the aiohttp library to make asynchronous HTTP requests, suitable
for simpler and lightweight scraping.
AsyncChromiumLoader
The AsyncChromiumLoader uses Playwright to launch a Chromium instance, which can handle JavaScript rendering and more complex web interactions.
Chromium is one of the browsers supported by Playwright, a library used to control browser automation.
Headless mode means that the browser is running without a graphical user interface, which is commonly used for web scraping.
from langchain_community.document_loaders import AsyncHtmlLoader
urls = ["https://www.espn.com", "https://lilianweng.github.io/posts/2023-06-23-agent/"]
loader = AsyncHtmlLoader(urls)
docs = loader.load()
API Reference:
Transformer
HTML2Text
HTML2Text provides a straightforward conversion of HTML content into plain text (with markdown-like formatting) without any specific tag manipulation.
It’s best suited for scenarios where the goal is to extract human-readable text without needing to manipulate specific HTML elements.
Beautiful Soup
Beautiful Soup offers more fine-grained control over HTML content, enabling specific tag extraction, removal, and content cleaning.
It’s suited for cases where you want to extract specific information and clean up the HTML content according to your needs.
from langchain_community.document_loaders import AsyncHtmlLoader
urls = ["https://www.espn.com", "https://lilianweng.github.io/posts/2023-06-23-agent/"]
loader = AsyncHtmlLoader(urls)
docs = loader.load()
API Reference:
Fetching pages: 100%|#############################################################################################################| 2/2 [00:00<00:00, 7.01it/s]
from langchain_community.document_transformers import Html2TextTransformer
html2text = Html2TextTransformer()
docs_transformed = html2text.transform_documents(docs)
docs_transformed[0].page_content[0:500]
API Reference:
"Skip to main content Skip to navigation\n\n<\n\n>\n\nMenu\n\n## ESPN\n\n * Search\n\n * * scores\n\n * NFL\n * MLB\n * NBA\n * NHL\n * Soccer\n * NCAAF\n * …\n\n * Women's World Cup\n * LLWS\n * NCAAM\n * NCAAW\n * Sports Betting\n * Boxing\n * CFL\n * NCAA\n * Cricket\n * F1\n * Golf\n * Horse\n * MMA\n * NASCAR\n * NBA G League\n * Olympic Sports\n * PLL\n * Racing\n * RN BB\n * RN FB\n * Rugby\n * Tennis\n * WNBA\n * WWE\n * X Games\n * XFL\n\n * More"
Scraping with extraction
LLM with function calling
Web scraping is challenging for many reasons.
One of them is the changing nature of modern websites’ layouts and content, which requires modifying scraping scripts to accommodate the changes.
Using Function (e.g., OpenAI) with an extraction chain, we avoid having to change your code constantly when websites change.
We’re using gpt-3.5-turbo-0613 to guarantee access to OpenAI Functions
feature (although this might be available to everyone by time of
writing).
We’re also keeping temperature at 0 to keep randomness of the LLM
down.
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(temperature=0, model="gpt-3.5-turbo-0613")
API Reference:
Define a schema
Next, you define a schema to specify what kind of data you want to extract.
Here, the key names matter as they tell the LLM what kind of information they want.
So, be as detailed as possible.
In this example, we want to scrape only news article’s name and summary from The Wall Street Journal website.
from langchain.chains import create_extraction_chain
schema = {
"properties": {
"news_article_title": {"type": "string"},
"news_article_summary": {"type": "string"},
},
"required": ["news_article_title", "news_article_summary"],
}
def extract(content: str, schema: dict):
return create_extraction_chain(schema=schema, llm=llm).run(content)
API Reference:
Run the web scraper w/ BeautifulSoup
As shown above, we’ll be using BeautifulSoupTransformer.
import pprint
from langchain_text_splitters import RecursiveCharacterTextSplitter
def scrape_with_playwright(urls, schema):
loader = AsyncChromiumLoader(urls)
docs = loader.load()
bs_transformer = BeautifulSoupTransformer()
docs_transformed = bs_transformer.transform_documents(
docs, tags_to_extract=["span"]
)
print("Extracting content with LLM")
# Grab the first 1000 tokens of the site
splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=1000, chunk_overlap=0
)
splits = splitter.split_documents(docs_transformed)
# Process the first split
extracted_content = extract(schema=schema, content=splits[0].page_content)
pprint.pprint(extracted_content)
return extracted_content
urls = ["https://www.wsj.com"]
extracted_content = scrape_with_playwright(urls, schema=schema)
API Reference:
Extracting content with LLM
[{'news_article_summary': 'The Americans will remain under house arrest until '
'they are allowed to return to the U.S. in coming '
'weeks, following a monthslong diplomatic push by '
'the Biden administration.',
'news_article_title': 'Four Americans Released From Iranian Prison'},
{'news_article_summary': 'Price pressures continued cooling last month, with '
'the CPI rising a mild 0.2% from June, likely '
'deterring the Federal Reserve from raising interest '
'rates at its September meeting.',
'news_article_title': 'Cooler July Inflation Opens Door to Fed Pause on '
'Rates'},
{'news_article_summary': 'The company has decided to eliminate 27 of its 30 '
'clothing labels, such as Lark & Ro and Goodthreads, '
'as it works to fend off antitrust scrutiny and cut '
'costs.',
'news_article_title': 'Amazon Cuts Dozens of House Brands'},
{'news_article_summary': 'President Biden’s order comes on top of a slowing '
'Chinese economy, Covid lockdowns and rising '
'tensions between the two powers.',
'news_article_title': 'U.S. Investment Ban on China Poised to Deepen Divide'},
{'news_article_summary': 'The proposed trial date in the '
'election-interference case comes on the same day as '
'the former president’s not guilty plea on '
'additional Mar-a-Lago charges.',
'news_article_title': 'Trump Should Be Tried in January, Prosecutors Tell '
'Judge'},
{'news_article_summary': 'The CEO who started in June says the platform has '
'“an entirely different road map” for the future.',
'news_article_title': 'Yaccarino Says X Is Watching Threads but Has Its Own '
'Vision'},
{'news_article_summary': 'Students foot the bill for flagship state '
'universities that pour money into new buildings and '
'programs with little pushback.',
'news_article_title': 'Colleges Spend Like There’s No Tomorrow. ‘These '
'Places Are Just Devouring Money.’'},
{'news_article_summary': 'Wildfires fanned by hurricane winds have torn '
'through parts of the Hawaiian island, devastating '
'the popular tourist town of Lahaina.',
'news_article_title': 'Maui Wildfires Leave at Least 36 Dead'},
{'news_article_summary': 'After its large armored push stalled, Kyiv has '
'fallen back on the kind of tactics that brought it '
'success earlier in the war.',
'news_article_title': 'Ukraine Uses Small-Unit Tactics to Retake Captured '
'Territory'},
{'news_article_summary': 'President Guillermo Lasso says the Aug. 20 election '
'will proceed, as the Andean country grapples with '
'rising drug gang violence.',
'news_article_title': 'Ecuador Declares State of Emergency After '
'Presidential Hopeful Killed'},
{'news_article_summary': 'This year’s hurricane season, which typically runs '
'from June to the end of November, has been '
'difficult to predict, climate scientists said.',
'news_article_title': 'Atlantic Hurricane Season Prediction Increased to '
'‘Above Normal,’ NOAA Says'},
{'news_article_summary': 'The NFL is raising the price of its NFL+ streaming '
'packages as it adds the NFL Network and RedZone.',
'news_article_title': 'NFL to Raise Price of NFL+ Streaming Packages as It '
'Adds NFL Network, RedZone'},
{'news_article_summary': 'Russia is planning a moon mission as part of the '
'new space race.',
'news_article_title': 'Russia’s Moon Mission and the New Space Race'},
{'news_article_summary': 'Tapestry’s $8.5 billion acquisition of Capri would '
'create a conglomerate with more than $12 billion in '
'annual sales, but it would still lack the '
'high-wattage labels and diversity that have fueled '
'LVMH’s success.',
'news_article_title': "Why the Coach and Kors Marriage Doesn't Scare LVMH"},
{'news_article_summary': 'The Supreme Court has blocked Purdue Pharma’s $6 '
'billion Sackler opioid settlement.',
'news_article_title': 'Supreme Court Blocks Purdue Pharma’s $6 Billion '
'Sackler Opioid Settlement'},
{'news_article_summary': 'The Social Security COLA is expected to rise in '
'2024, but not by a lot.',
'news_article_title': 'Social Security COLA Expected to Rise in 2024, but '
'Not by a Lot'}]
We can compare the headlines scraped to the page:

Looking at the LangSmith trace, we can see what is going on under the hood:
- It’s following what is explained in the extraction.
- We call the
information_extractionfunction on the input text. - It will attempt to populate the provided schema from the url content.
Research automation
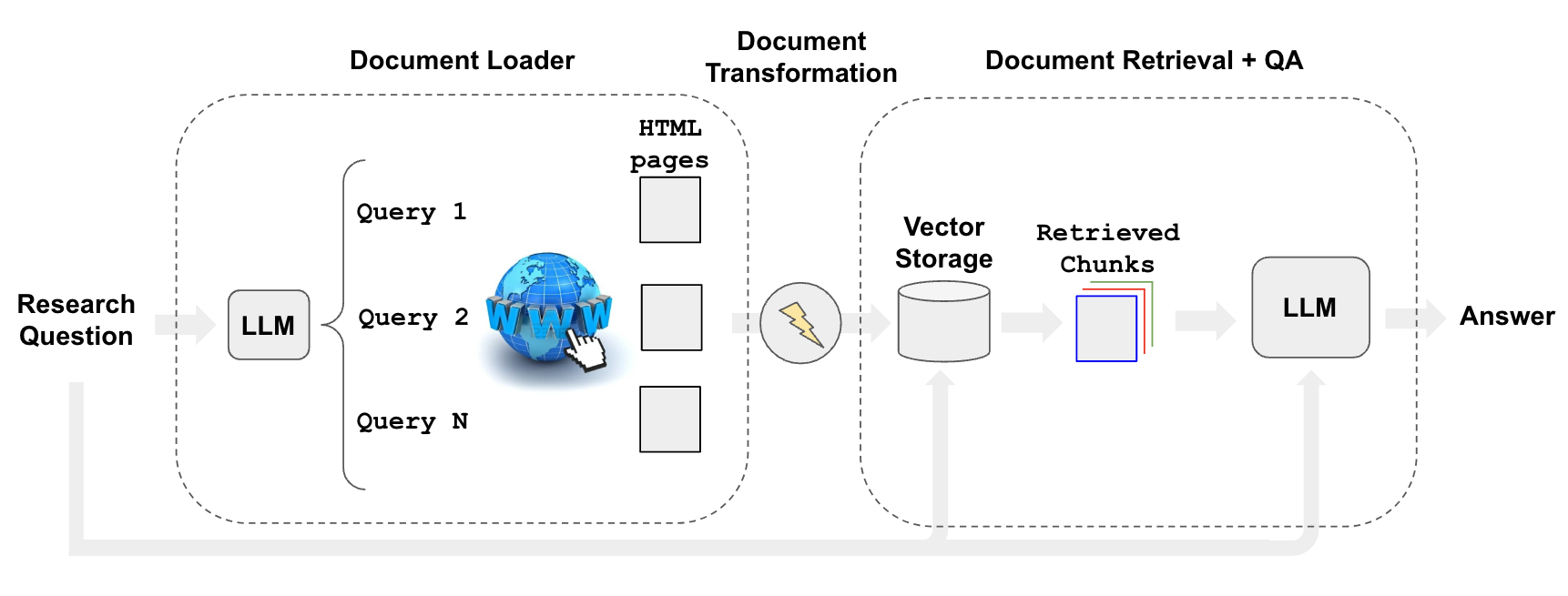
Related to scraping, we may want to answer specific questions using searched content.
We can automate the process of web
research using a
retriever, such as the WebResearchRetriever.
Copy requirements from here:
pip install -r requirements.txt
Set GOOGLE_CSE_ID and GOOGLE_API_KEY.
from langchain.retrievers.web_research import WebResearchRetriever
from langchain_chroma import Chroma
from langchain_community.utilities import GoogleSearchAPIWrapper
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
# Vectorstore
vectorstore = Chroma(
embedding_function=OpenAIEmbeddings(), persist_directory="./chroma_db_oai"
)
# LLM
llm = ChatOpenAI(temperature=0)
# Search
search = GoogleSearchAPIWrapper()
Initialize retriever with the above tools to:
- Use an LLM to generate multiple relevant search queries (one LLM call)
- Execute a search for each query
- Choose the top K links per query (multiple search calls in parallel)
- Load the information from all chosen links (scrape pages in parallel)
- Index those documents into a vectorstore
- Find the most relevant documents for each original generated search query
# Initialize
web_research_retriever = WebResearchRetriever.from_llm(
vectorstore=vectorstore, llm=llm, search=search
)
# Run
import logging
logging.basicConfig()
logging.getLogger("langchain.retrievers.web_research").setLevel(logging.INFO)
from langchain.chains import RetrievalQAWithSourcesChain
user_input = "How do LLM Powered Autonomous Agents work?"
qa_chain = RetrievalQAWithSourcesChain.from_chain_type(
llm, retriever=web_research_retriever
)
result = qa_chain({"question": user_input})
result
API Reference:
INFO:langchain.retrievers.web_research:Generating questions for Google Search ...
INFO:langchain.retrievers.web_research:Questions for Google Search (raw): {'question': 'How do LLM Powered Autonomous Agents work?', 'text': LineList(lines=['1. What is the functioning principle of LLM Powered Autonomous Agents?\n', '2. How do LLM Powered Autonomous Agents operate?\n'])}
INFO:langchain.retrievers.web_research:Questions for Google Search: ['1. What is the functioning principle of LLM Powered Autonomous Agents?\n', '2. How do LLM Powered Autonomous Agents operate?\n']
INFO:langchain.retrievers.web_research:Searching for relevant urls ...
INFO:langchain.retrievers.web_research:Searching for relevant urls ...
INFO:langchain.retrievers.web_research:Search results: [{'title': 'LLM Powered Autonomous Agents | Hacker News', 'link': 'https://news.ycombinator.com/item?id=36488871', 'snippet': 'Jun 26, 2023 ... Exactly. A temperature of 0 means you always pick the highest probability token (i.e. the "max" function), while a temperature of 1 means you\xa0...'}]
INFO:langchain.retrievers.web_research:Searching for relevant urls ...
INFO:langchain.retrievers.web_research:Search results: [{'title': "LLM Powered Autonomous Agents | Lil'Log", 'link': 'https://lilianweng.github.io/posts/2023-06-23-agent/', 'snippet': 'Jun 23, 2023 ... Task decomposition can be done (1) by LLM with simple prompting like "Steps for XYZ.\\n1." , "What are the subgoals for achieving XYZ?" , (2) by\xa0...'}]
INFO:langchain.retrievers.web_research:New URLs to load: []
INFO:langchain.retrievers.web_research:Grabbing most relevant splits from urls...
{'question': 'How do LLM Powered Autonomous Agents work?',
'answer': "LLM-powered autonomous agents work by using LLM as the agent's brain, complemented by several key components such as planning, memory, and tool use. In terms of planning, the agent breaks down large tasks into smaller subgoals and can reflect and refine its actions based on past experiences. Memory is divided into short-term memory, which is used for in-context learning, and long-term memory, which allows the agent to retain and recall information over extended periods. Tool use involves the agent calling external APIs for additional information. These agents have been used in various applications, including scientific discovery and generative agents simulation.",
'sources': ''}
Going deeper
- Here’s a app that wraps this retriever with a lighweight UI.
Question answering over a website
To answer questions over a specific website, you can use Apify’s Website Content Crawler Actor, which can deeply crawl websites such as documentation, knowledge bases, help centers, or blogs, and extract text content from the web pages.
In the example below, we will deeply crawl the Python documentation of LangChain’s Chat LLM models and answer a question over it.
First, install the requirements
pip install apify-client langchain-openai langchain
Next, set OPENAI_API_KEY and APIFY_API_TOKEN in your environment
variables.
The full code follows:
from langchain.indexes import VectorstoreIndexCreator
from langchain_community.docstore.document import Document
from langchain_community.utilities import ApifyWrapper
apify = ApifyWrapper()
# Call the Actor to obtain text from the crawled webpages
loader = apify.call_actor(
actor_id="apify/website-content-crawler",
run_input={"startUrls": [{"url": "/docs/integrations/chat/"}]},
dataset_mapping_function=lambda item: Document(
page_content=item["text"] or "", metadata={"source": item["url"]}
),
)
# Create a vector store based on the crawled data
index = VectorstoreIndexCreator().from_loaders([loader])
# Query the vector store
query = "Are any OpenAI chat models integrated in LangChain?"
result = index.query(query)
print(result)
API Reference:
Yes, LangChain offers integration with OpenAI chat models. You can use the ChatOpenAI class to interact with OpenAI models.